

AI – The Blinking Red Warning Light
By Dr Simon Shakespeare

In the second post of his series, Simon Shakespeare responds to a concern that AI might soon hit some long-anticipated roadblocks and finds reassurance in the many other AI tools still left in the engineer’s toolbox.
One major concern developers have about mainstream AI is the fundamental approach used to make artificial neural networks learn. Many believe that a long-standing blockage lies ahead and that cracks are already showing in the approach currently being used. The focus of this concern has been on the learning algorithm, called back-propagation, which is commonly used to train artificial neural networks. It’s been around since the 1980s and researchers are yet to find a more efficient method. Hence, it is worth reporting on some possible alternatives, such as methods based on evolution or approaches inspired by biology. Machine learning doesn’t need to be perfect to be useful, but we should be reassured that there are still many unexplored approaches that may overcome some of the roadblocks ahead.
Although the back-propagation algorithm has become the primary method of training artificial neural networks, there are many different approaches to tackling the way systems learn. Gary Marcus, a professor at New York University, backs up this view and said in one of his essays about the current approach that it was not a universal solvent, but one tool among many [1].
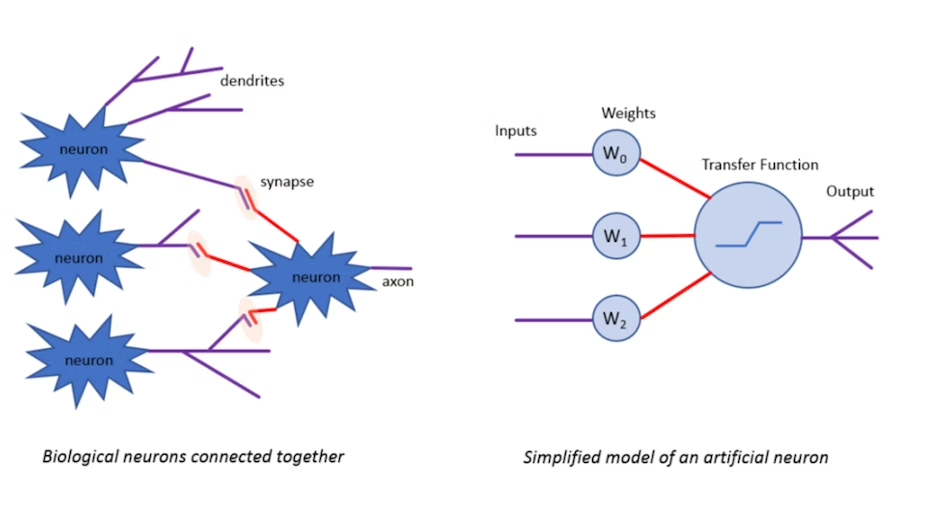
When we talk about learning algorithms, we are really talking about a way of changing how much influence each input (of many), will have before combining them to create a single output. This method of changing the weighting of each input is the key to how a network of artificial neurons learns to model data that is presented to it. By feeding the outputs from one layer of neurons into the inputs of a second layer, a neural network can be created. Recent successes in the fields of image recognition are based on artificial neural networks – these were being used back in the 1990s without much success. Back then, error rates were too large, the networks and training datasets too small and processing power insufficient to make much use of the technology.
One of the magical incantations to make this old tech learn was devised by Geoffrey Hinton, a professor at Toronto Tech, in 1984. His algorithmic method of back-propagation allowed multiple layers of neurons to be trained by nudging the weights of each connection to reduce the error terms. These are the origins of modern deep networks. For reasons that, even Hinton guiltily admits, we don’t understand, the more layers used, the more accurate the network becomes. Indeed, even Hinton who invented back-propagation is deeply suspicious of its usefulness going forward. At an AI conference in Toronto last September, he was quoted as saying, “My view is throw it all away and start again.” [2]
The lack of theory underpinning modern network designs doesn’t detract from the usefulness of developed systems, but it does make developers uneasy and makes development a game of heuristic guess-work, rather than predictable construction. The broad hope is that this will change as the field matures, but there are still nagging doubts about the methods used to train neural architectures. This is concerning because there have been relatively few improvements in the training approach since then and little consensus about what comes next. It does seem likely that modern attempts to build on these foundations are going to hit a roadblock that stops it advancing any further.
The approach of creating multiple layers of neurons has some basis in neurology, and of course the artificial neuron was originally conceived as a simplified copy from nature. Perhaps it’s just the limited number of artificial neurons we are currently using rather than the network structure, but we are still far away from being able to simulate the complexity captured in the human brain. Perhaps it is a combination of the limited number of neurons and limited number of interconnections that is the problem. Our current networks of artificial neurons also have vastly fewer interconnections, perhaps 1,000 per neuron, compared to their biological cousins that can have more than 10,000 connections per neuron. These are just physical limits imposed on us by the cost of processing hardware and memory. If this were the only issue, then simply waiting a few years for cheaper hardware should solve the learning problem.
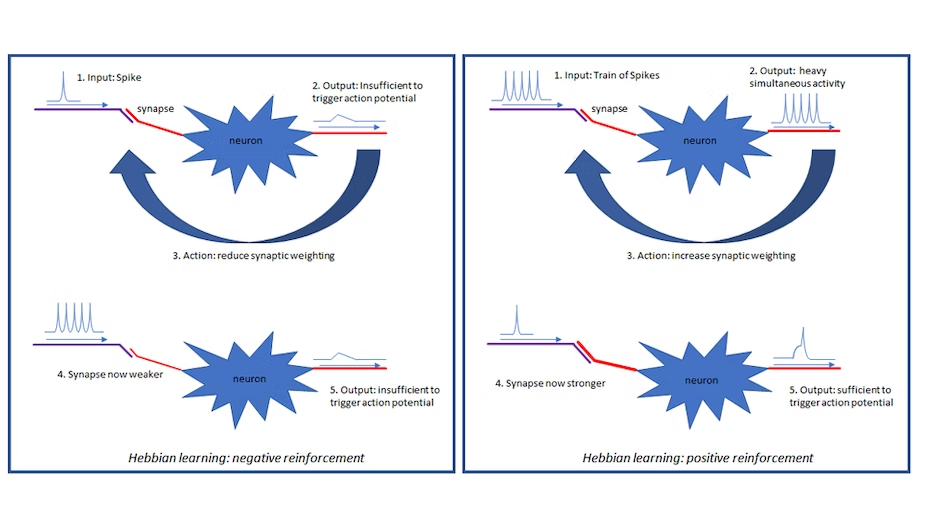
Neuroscientists would point out that the other big difference is that biological neurons don’t use back-propagation when learning new tasks. Instead, they use a form of Hebbian learning. How this works can be summarised by a helpful mantra: “neurons that fire together, wire together”. Learning occurs by strengthening the connection between neurons that are active at the same time and weakening connections where there is no simultaneous activity. Biological neurons utilise the timing information from spikes, or impulses, to perform this trick of strengthening or weakening the synaptic connections. That such a simple mechanism is all there is to the human brain seems unlikely, however, and it’s likely that there is still more we need to uncover about the operation of this awesome organ. We are already learning about new and differentiated neurons and it’s likely that these are an important part of the puzzle. Of course, Hebbian learning might also be a quirk of evolution rather than the best approach to training a network. Without evolution and biochemistry to hold back investigation into the area, there might be more efficient approaches to use when developing artificial neural learning systems.
Wishing to learn more about the approach of Hebbian learning using spikes, I spoke with Dr Volker Steuber who is the Head of the Biocomputation Research Group at the University of Hertfordshire. He and his group have been investigating this area for many years. In our conversation, we mused that a way of bypassing the roadblock of back-propagation might be found by moving from our simplistic models of neurons to more complex versions, along with a different approach to learning. Possibly, an algorithm that evolves simple spiking neural networks (SNNs) as described by Steuber and his colleagues might be the future of a more elegant AI that simulates human learning more effectively than current approaches [3].
We are not limited to one approach, of course, and if evolutionary pressures resulted in human general intelligence then perhaps it could be pressed into improving silicon intelligence. Simulated evolution has been used successfully in training neural networks and it remains a useful tool that we could use in the future. NeuroEvolution, Genetic Programming and Genetic Algorithms all leverage the power of evolution, but they are all computationally intensive. Although humanity is impatient to wait another million years for silicon to evolve intelligence, perhaps hardware improvement will come to the rescue with this approach. Computing power per dollar continues to double every two years and will probably continue to do so as designs with multiple processing cores continue to be developed.
Finally, it is worth considering that instead of seeking to replace back-propagation with something better we simply learn to work around its limitations. Perhaps the best example of this approach are the exciting developments in a class of systems called Generative Adversarial Networks [4, 5]. These are networks that train themselves by moving the fitness functions used to learn to a much higher level, but still use back-propagation at the base. This fascinating area of co-evolving systems is something to explore in detail in another post.
Many researchers are driven by the desire to achieve better machine learning algorithms. Current techniques of building networks based on massive data sets are unlikely to be the solution in the long term. There are several tantalising possibilities to where we go from here, and the worry over back-propagation might prove to be unwarranted. The brittleness and massive data hunger of existing technique will likely give way as a better high-level approach is adopted. It’s quite possible that back-propagation will still be the choice of network learning at the base even when these new high-level techniques are bolted on to the top. Creating more robust artificial intelligence was always going to be challenging, but there are still many other tools left in the engineer’s toolbox.
This blog was mostly a response to this fascinating article in MIT’s technology review that can be found here.
Links to other reading on the topic:

Related Articles

